
Como mencioné en el post anterior, recientemente comencé a utilizar Dapper para algunos proyectos en mi trabajo y a causa de ellos tuve la necesidad de migrar algunas operaciones al otro sistema y para ello se deben sincronizar datos entre los dos sistemas.
Contexto
Estos datos que necesitaba sincronizar son listas pero existen algunas que dependen de otra lista, por ejemplo, si se tratara de un punto de venta es probable tengamos entidades como Caja y ésta dependería de Sucursal.
Bajo éste escenario el procedimiento a seguir es el siguiente:
- Se tienen dos sistemas a sincronizar (S1 y S2)
- Se creará una aplicación de consola que recabará las listas de S1 y las enviará a S2
- S2 contará con un WebApi para recibir las listas enviadas por S1
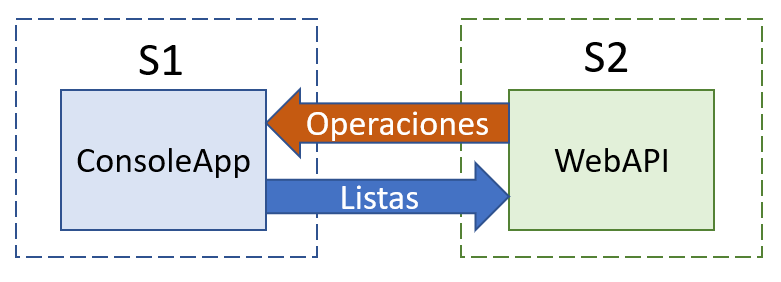
Bien ahora, desde el punto de vista de S2 tenemos los siguientes escenarios:
- El elemento recibido es nuevo y hay que registrarlo
- El elemento ya existe y se debe actualizar en S2
Desglosando el Problema
Como mencioné anteriormente, hay listas que dependen de otra y esto nos genera un caso “especial” ya que si se agregan elementos nuevos a una lista que tiene dependencias y estas mismas aun no se han registrado esto genera un conflicto en S2 al tratar de registrar el elemento recibido.
Ejemplo: Supongamos que en S1 existen las entidades Sucursal y Caja, se entiende que la caja pertenece a alguna sucursal, dicho en otras palabras, la caja depende de la sucursal, esto implica que para poder registrar una caja ya debe estar registrada la sucursal a la que pertenece, entonces: ¿Qué pasaría si recibimos una caja de una sucursal nueva y aun no se registra la sucursal?, obviamente esto es un error que se soluciona de dos formas:
- Asegurarnos de que la sincronización dé prioridad a las listas que tengan dependencias.
- Si el elemento recibido tiene una dependencia que no existe, la dependencia se registra “en blanco” y al recibir la lista de la que depende se actualizaría la dependencia “en blanco”.
Para éste caso donde la sincronización será automática no creo conveniente seguir el camino de la opción número 1 ya que si el sistema crece podríamos toparnos con referencias circulares (cosa que ya me ha pasado anteriormente) y esto provocaría otro problema, así que opté por seguir la opción número 2.
Patrón Unit of Work
Ahora que he decidido registrar las dependencias “en blanco” necesito hacer las inserciones de las dependencias en una transacción y para ello utilizaré el patrón UnitOfWork y para ello usare la siguiente clase:
public class UnitOfWork : IDisposable
{
public IDbConnection Connection { get; }
public IDbTransaction Transaction { get; }
public UnitOfWork()
{
Connection = Repository.GetConnection();
Connection.Open();
Transaction = Connection.BeginTransaction();
}
public void Commit() => Transaction.Commit();
public void Rollback() => Transaction.Rollback();
public void Dispose()
{
Transaction?.Dispose();
Connection?.Dispose();
}
}Esta clase será la encargada crear la conexión a la base de datos y de hacer commit o rollback a la transacción.
A continuación les muestro como usar la clase UnitOfWork:
public static Result<long?> InsertCaja(CajaRequest request)
{
using (var unit = new UnitOfWork())
{
try
{
Result<long?> result = InsertCajaInterna(request, unit.Connection, unit.Transaction);
unit.Commit();
return result;
}
catch (Exception ex)
{
unit.Rollback();
log.Error($"Message: {ex.Message} | InnerException: {ex.InnerException} | StackTrace: {ex.StackTrace}");
return Result<long?>.Fail("Ocurrio un error al registrar la caja");
}
}
}Como se puede ver creé una función “Interna” pasando como parámetros tanto la conexión como la transacción, de esta manera todas las operaciones de base de datos se harán en conjunto.
NOTA: Estoy utilizando la clase Result para manejar las respuestas de las operaciones, su código es el siguiente:
C#public class Result { protected Result() { } public bool Success { get; protected set; } public string Message { get; protected set; } public static Result Ok(string message = "") => new Result { Success = true, Message = message }; public static Result Fail(string message) => new Result { Success = false, Message = message }; } public class Result<T> : Result { public T Data { get; set; } = default; public static Result<T> Ok(T data, string message = "") => new Result<T> { Success = true, Message = message, Data = data }; public new static Result<T> Fail(string message) => new Result<T> { Success = false, Message = message, Data = default }; }
A continuación te muestro el código de la función InsertCajaInterna:
private static Result<long?> InsertCajaInterna(CajaRequest request, IDbConnection con, IDbTransaction trx)
{
long? sucursalId = null;
// Se obtiene la sucursal
sucursalId = con.ExecuteScalar<long?>(
"SELECT SucursalId FROM Sucursal WHERE IdExterno = @IdExternoSucursal"
, new { IdExternoSucursal = request.sucursalId }, trx);
// Si no existe la sucursal se registra en blanco
if (!sucursalId.HasValue)
{
Result<long?> resultSucursal = InsertSucursalInterna(new SucursalRequest
{ idExterno = request.sucursalId, IsEmptiInsert = true }, con, trx);
sucursalId = resultSucursal.Data;
if (!sucursalId.HasValue)
return Result<long?>.Fail("No se pudo identificar la sucursal");
}
// Se valida si existe una caja con el mismo IdExterno
Result<long?> cajaId = con.ExecuteScalar<long?>("SELECT CajaId FROM Caja WHERE IdExterno = @IdExterno",
new { IdExterno = request.idExterno }, trx);
if (!cajaId.HasValue)
{
// Se inserta la caja nueva
cajaId = con.ExecuteScalar<long?>(
"INSERT INTO Caja (IdExterno, NombreCaja, SucursalId) " +
" VALUES (@IdExterno, UPPER(@NombreCaja), @SucursalId); " +
"SELECT SCOPE_IDENTITY();"
, new
{
IdExterno = request.idExterno,
NombreCaja = request.nombreCaja,
SucursalId = sucursalId.Value
}, trx);
}
else
{
// Se actualiza la caja existente
con.Execute(
"UPDATE Caja SET NombreCaja = UPPER(@NombreCaja), SucursalId = @SucursalId " +
"WHERE IdExterno = @IdExterno "
, new
{
IdExterno = request.idExterno,
NombreCaja = request.nombreCaja,
SucursalId = sucursalId.Value
}, trx);
}
log.Info($"CajaId: {cajaId} | Nombre: '{request.nombreCaja}' | SucursalId: {sucursalId} | IdExterno: {request.idExterno}");
return Result<long?>.Ok(cajaId, "Caja registrada correctamente");
}De esta manera he conseguido insertar la caja y su dependencia en una transacción para mantener la integridad de los datos.
¿Cuándo usar Unit of Work?
- Cuando se requieren múltiples operaciones dependientes entre sí.
- Procesos de negocio complejos.
Conclusión
Implementar el patrón Unit of Work con Dapper no es obligatorio, pero existen escenarios donde se requiere que múltiples operaciones se ejecuten en conjunto, y es aquí donde se vuelve una pieza clave para mantener la integridad de los datos.
